Why do we need it ?
First of all note that "Semantic Web" is sometimes used as a synonym for "Web 3.0", though each term's definition varies. As far as I can tell, Semantic Web is the main component of Web 3.0.In order to answer this question, we need to first understand what is wrong with today's www ?
Limitations of HTML
Currently, the World Wide Web is based mainly on documents written in Hypertext Markup Language (HTML), a markup convention that is used for coding a body of text interspersed with multimedia objects such as images and interactive forms. Metadata tags provide a method by which computers can categorise the content of web pages, for example: [3]
"The challenge for the design of the
Semantic Web is not to
make a web infrastructure that is as
smart as possible; it is to make an infrastructure that is most appropriate to the job of integrating
information on the Web." [1]
<meta name="keywords" content="computing, computer studies, computer" /> <meta name="description" content="Cheap widgets for sale" /> <meta name="author" content="John Doe" />
When a web-browser renders this, one can create and present a page that lists items for sale. HTML is not able to assert the connections between tags. For instance, it is not capable of showing that "item number X586172 is an Acme Gizmo with a retail price of €199", Rather, HTML can only say that the span of text "X586172" is something that should be positioned near "Acme Gizmo" and "€199", etc. There is no way to say "this is a catalog" or even to establish that "Acme Gizmo" is a kind of title or that "€199" is a price. [3]
Basically it is designed for humans to understand the content, not for machines. When machines need to make use of the content, third party applications or some software agents are needed for this purpose. That's why it basically depends on human interaction to come to conclusions ( making multiple queries in google to find out where I should go for a dinner at the weekend ) .
Basics of Semantic Web
The Semantic Web involves publishing in languages specifically designed for data: Resource Description Framework (RDF), Web Ontology Language (OWL), and Extensible Markup Language (XML). HTML describes documents and the links between them. RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts.
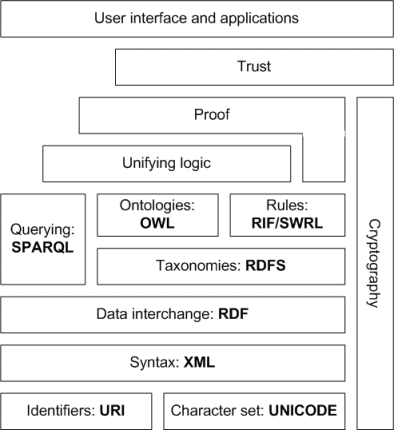
By the help of these concepts ( Later, we will go into particulars), content may manifest itself as descriptive data stored in Web-accessible databases.
The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content. In this way, a machine can process knowledge itself, instead of text, using processes similar to human deductive reasoning and inference, thereby obtaining more meaningful results and helping computers to perform automated information gathering and research.[3]
Tim Berners-Lee has described the semantic web as a component of 'Web 3.0'.[16]
People keep asking what Web 3.0 is. I think maybe when you've got an overlay of scalable vector graphics – everything rippling and folding and looking misty — on Web 2.0 and access to a semantic Web integrated across a huge space of data, you'll have access to an unbelievable data resource..."
— Tim Berners-Lee, 2006
Limitations - Challenges in Semantic Web
Some of the challenges for the Semantic Web include vastness, vagueness, uncertainty, inconsistency, and deceit. Automated reasoning systems will have to deal with all of these issues in order to deliver on the promise of the Semantic Web.[3]
As we go into particulars of this technology, you will be able to understand why it still needs more time to completely get ready.
[1] Semantic.Web.for.the.Working.Ontologist.-.Allemang.&.Hendler,.2ed,.Elsevier,2011
[2] http://cwi.unik.no/wiki/Basics_of_Semantics
[3] http://en.wikipedia.org/wiki/Semantic_Web
No comments:
Post a Comment